Neural Networks in Glucose Prediction
Abstract:
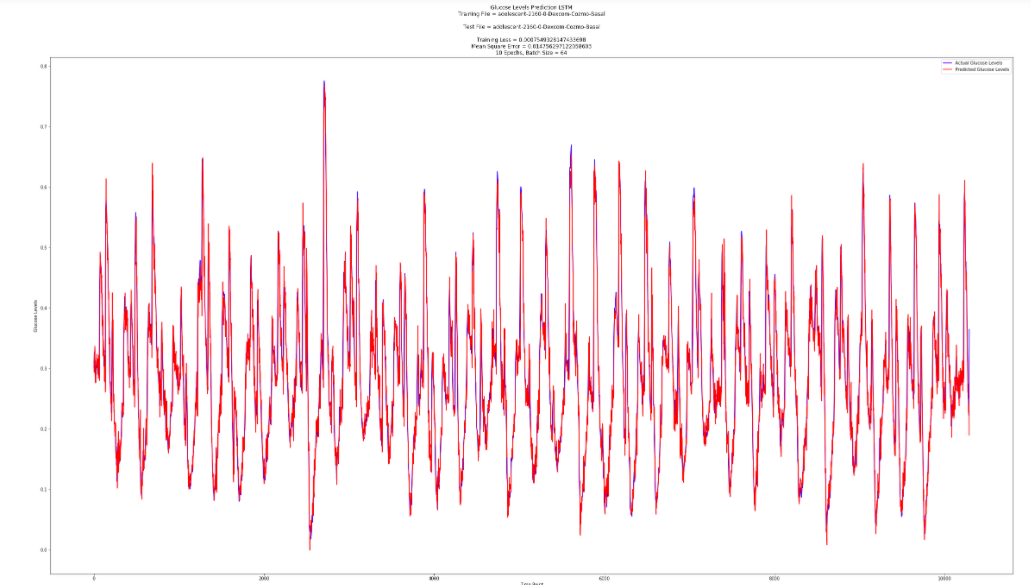
This paper aims to build a model for glucose prediction using the preferred architecture. According to National Diabetes Statistics Report from the Centers for Disease Control (CDC), by 2020, there are 34.2 million Americans with Diabetes, which is 1 in every 10 people. Therefore, glucose prediction, with its potential use in the "artificial pancreas”, has become crucial in the realm of managing patients’ glucose levels and taking necessary precautions. In this paper, we develop a glucose prediction algorithm for patients to predict their blood sugar level in the future 30 minutes and 60 minutes with the input data of the last 4 hours. The general data set from a Continuous Glucose Monitoring (CGM) simulator is of three input fields – glucose levels, insulin, and time. The model is built by Recurrent Neural Network (RNN) and Long Short-Term Memory network (LSTM). Eventually, the results are evaluated by the mean squared error (MSE) between the actual blood sugar levels and the predicted ones. The mean value of the best MSE (unscaled) of the three out of ten patients in 30 minutes is 0.0138, while the mean value in 60 minutes is 0.0093. From the results, we can see that the performance of the prediction model is fairly accurate. As a result, we can conclude that applying LSTM to the task of predicting blood sugar level in the future is a favorable choice.Bibliography/Citations:
Additional Project Information
Research Plan:
Rationale:
According to National Diabetes Statistics Report from the Centers for Disease Control (CDC), by 2020, there are 34.2 million Americans with Diabetes. That is,1 in every 10 people suffer from diabetes. Therefore, glucose prediction has become crucial in managing patients’ glucose levels and helping patients track any upcoming risk of high glucose levels. There is a wide range of machine learning methods, but few can address the problem of predicting glucose levels effectively. For one, the large number of data required to predict future glucose levels makes the whole process challenging. For another thing, it’s hard to solve the time-series problem with a forward network. Therefore, the goal of this research is to determine a neural network that can carry out the best performance in glucose prediction.
Hypothesis:
Because glucose prediction requires a method to deal with time-series problems, a recurrent neural network would be optimal to execute the performance of glucose prediction.
Research Questions:
- Which kind of neural network is the most optimal for glucose prediction?
- Between the two recurrent neural networks -- simple RNN and LSTM, which one would execute a better result for glucose prediction, based on both the MSE and the line graph?
- How do the values of each parameter affect the test result (mean squared error) for the model?
- What are some ways to reduce the testing time and increase the efficiency of the model?
Procedures:
- Determine the number and type of information to collect (10 patients data in 365 days, 288 time points per day and a total number of 103680 time points, with data of glucose level and insulin injection amount)
- Gather data from UVA/Padova T1D simulator.
- Observe the pattern of the data by generating a line graph for each patient in the range of one year and predict by hand the likelihood of encountering extreme glucose levels
- Process the collected data with Minimum-Maximum normalization method
- Determine the time frame and add a sliding window to the data
- Split the collected data into training data sets and testing data sets
- Design a testing plan (including optimizing the parameters: 1) Build the model with simple RNN and test the model; 2) Build the model with LSTM and test the model
- Compare the mean squared error (MSE) values of the results of each patient and analyze the generated line graphs between the predicted glucose level and the actual glucose level
- Determine the most optimal model to complete the task of glucose prediction
Questions and Answers
1. What was the major objective of your project and what was your plan to achieve it?
a. Was that goal the result of any specific situation, experience, or problem you encountered?
b. Were you trying to solve a problem, answer a question, or test a hypothesis?
2020 has given the healthcare system a big challenge in terms of the healthcare system. At the beginning of March, daily supplies ran short in grocery stores, so were the rooms at hospitals. Efficiency has become the key, as we live in a pandemic season. Through my project, I hope to apply my knowledge -- artificial intelligence -- to the healthcare industry, where I can use machine learning skills to find patterns in patients’ data and look for a solution to a long-standing health issue in a short amount of time. And I choose to address the issue of diabetes because it’s a problem faced by a lot of Americans and people around the globe.
The major problem of this project is to determine the most optimal neural network to build the glucose prediction model, along with some subquestions, regarding the accuracy and efficiency of the model. My plan is to build several models with different neural networks. Then I would use the collected data from a simulator to test the models and evaluate their performance based on the mean squared error and line graph between the predicted and actual value. While building the model, I would use the training data set to try different parameters in order to determine the most optimal ones for actual testing.
2. What were the major tasks you had to perform in order to complete your project?
a. For teams, describe what each member worked on.
I divide all procedures into two categories -- preparing and testing.
For preparation, I put CSV files containing data in Python. I also need to process the data by normalizing it with Minimum-Maximum normalization and adding a sliding window to keep track of the past four hours' data, which would then be used to predict the future glucose level. In addition, splitting the entire data set into training and testing data sets is part of the preparation process. After processing all data, it’s important to build the model, which comes with the process of building models with different neural networks as well as the process of parameter optimization.
After building the models, it’s important to use a table to record all the mean squared error values for each trial. Since the data is collected from 10 patients in a year, all those 10 patients’ data would be used to test each model. After putting all the data into the models and generating all mean squared error, compare the results and the line graphs to draw a conclusion.
3. What is new or novel about your project?
a. Is there some aspect of your project's objective, or how you achieved it that you haven't done before?
b. Is your project's objective, or the way you implemented it, different from anything you have seen?
c. If you believe your work to be unique in some way, what research have you done to confirm that it is?
In my project, other than determining the most accurate model to predict glucose levels, I also try to find the most effective way to complete the task, which I believe could give people new ideas on glucose prediction. I’ve read some research papers on glucose prediction models, and some of them mainly focus on the models they employ while predicting glucose levels. For example, “A Deep Learning Algorithm For Personalized Blood Glucose Prediction” focused on using the convolutional neural network to complete the task, and they focus solely on the best root mean squared error values. However, my project also discusses the importance of efficiency other than accuracy. Even though more work might need to be done before determining the factors that affect efficiency, the process that my project has gone through might give some new ideas on possible ways to shorten the testing time of the model.
4. What was the most challenging part of completing your project?
a. What problems did you encounter, and how did you overcome them?
b. What did you learn from overcoming these problems?
In general, coding demands debugging. Fixing all the bugs gives a sense of accomplishment, but the process can be stressful. When I was adding the sliding window, I had to calculate the time points (the past 4 hours) to determine the size of the sliding window, which needs to slide down every time point as time goes by.
In addition, slowing down the testing time is another thing I’ve been trying to achieve as I built and trained my model. While I tried my best to optimize the parameters (such as the batch size), I realized that even though the mean squared error would be fairly similar, the time might double or triple with different parameters. As a result, running a lot of cases to test the time used to predict glucose level was another problem I faced.
There are a lot of steps in the project, and each one of the steps requires patience. It’s different from a one-time task where I can simply finish the task and never look at it again. Rather, it’s a project where each step matters, as all of the procedures are built on top of the previous ones. I need to come back to it frequently, as I might be inspired by some ways to improve the efficiency of the model. Also, by trying out different methods, different parameters, it becomes inspiring to see how the model can result in so many variations. What I realized during the process was that paying attention to each small detail and staying curious about how to fix a problem became important to the progress.
5. If you were going to do this project again, are there any things you would you do differently the next time?
If I could start the project again, one thing I would tell myself to be aware of would be to pay attention to time. Sometimes in the project, I tended to procrastinate as I thought a certain part of the project was easy. For instance, at first, I ignored that building the model would include so many trying processes. As I waited until the last planned date for that step, I still had little progress. It would delay my plan if I couldn’t carefully follow my plan. So I would recommend myself to look at the big picture.
6. Did working on this project give you any ideas for other projects?
Yes, after this project, I am planning to start another glucose prediction model on predicting hypoglycemia moments for diabetes patients. In my current project, I can predict patients’ future glucose levels. And since when patients are asleep, it’s hard for them to know if they experience hypoglycemia, which would be detrimental to their health conditions if their glucose level becomes too low. In order to make it more convenient for the patients to check for future extreme values, I could categorize the data into two classes, hypoglycemia or no hypoglycemia. The process should be similar, and it would be one step further to help predict glucose levels.