Modeling and visualizing the SARS-CoV-2 mutation based on geographical regions and time
Abstract:
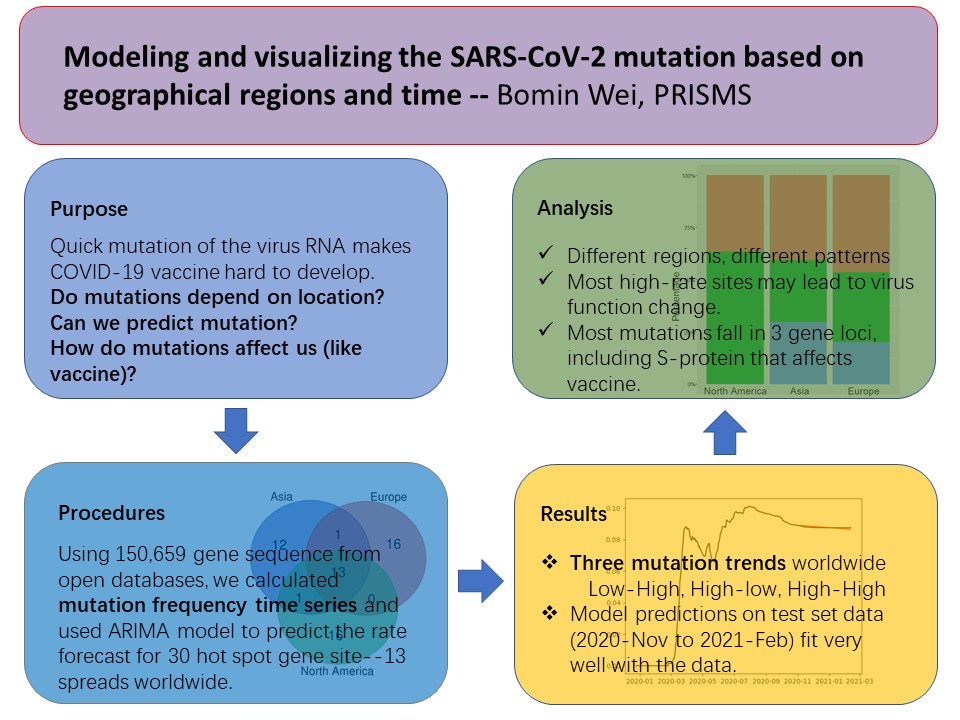
The Coronavirus Disease 2019 (COVID-19) epidemic was first detected in late-December 2019 in Wuhan, China. So far, it has caused more than one hundred million confirmed cases and over two million deaths in the world. The original genome of SARS-CoV-2 contains several open reading frames (ORFs) that encode the spike (S) glycoprotein, the replicase polyprotein, membrane (M), envelope (E), nucleocapsid (N) proteins, and accessory protein. 150,659 COVID-19 sequences were collected from China National Center for Bioinformation 2019 Novel Coronavirus Resource. Based on the previous phylogenomic analysis, I found three major branches of the virus RNA genomic mutation located in Asia, America, and Europe which is consistent with other studies. I selected sites with high mutation frequencies from Asia, America, and Europe. There are only 13 sites that have a high mutation frequency in all of these three regions. It infers that the viral mutations are highly dependent on their location and different locations have specific mutations. Most mutations can lead to amino acid substitutions. These substitutions occurred in 3/5'UTR, S/N/M protein, and ORF1ab/3a/8/10. Thus, the mutations may affect the pathogenesis of the virus. Additionally, I developed a prediction model for the frequency change of these top mutation sites during the spread of the disease. The MSE values show that the prediction is reliable. It provides a reference for researchers on different continents. I plan to develop a website to visualize the prediction model of SARS-CoV-2 mutation in future work. Vaccines developed in different countries may have diverse efficiencies in other countries. The similarity of genomes in different countries can indirectly reflect the efficiency of vaccines while there is no direct information. Our system can provide local residents with an alternative way to assess the availability of vaccines.Bibliography/Citations:
1 Giorgi, G. et al. COVID-19-Related Mental Health Effects in the Workplace: A Narrative Review. Int J Environ Res Public Health 17, doi:10.3390/ijerph17217857 (2020).
2 Walls, A. C. et al. Structure, Function, and Antigenicity of the SARS-CoV-2 Spike Glycoprotein. Cell 181, 281-292 e286, doi:10.1016/j.cell.2020.02.058 (2020).
3 Abdullahi, I. N. et al. Implications of SARS-CoV-2 genetic diversity and mutations on pathogenicity of the COVID-19 and biomedical interventions. J Taibah Univ Med Sci 15, 258-264, doi:10.1016/j.jtumed.2020.06.005 (2020).
4 Makizako, H. et al. Exercise and Horticultural Programs for Older Adults with Depressive Symptoms and Memory Problems: A Randomized Controlled Trial. J Clin Med 9, doi:10.3390/jcm9010099 (2019).
5 Gong, Z. et al. An online coronavirus analysis platform from the National Genomics Data Center. Zool Res 41, 705-708, doi:10.24272/j.issn.2095-8137.2020.065 (2020).
6 Wu, F. et al. Author Correction: A new coronavirus associated with human respiratory disease in China. Nature 580, E7, doi:10.1038/s41586-020-2202-3 (2020).
7 Shang, J. et al. Cell entry mechanisms of SARS-CoV-2. Proc Natl Acad Sci U S A 117, 11727-11734, doi:10.1073/pnas.2003138117 (2020).
8 Sternberg, A. & Naujokat, C. Structural features of coronavirus SARS-CoV-2 spike protein: Targets for vaccination. Life Sci 257, 118056, doi:10.1016/j.lfs.2020.118056 (2020).
Additional Project Information
Research Plan:
Rationale:
The Coronavirus Disease 2019 (COVID-19) epidemic was first detected in late-December 2019 in Wuhan, China. So far, it has caused tens of millions of confirmed cases and millions of deaths over the world. The COVID-19 is caused by a novel evolutionary divergent RNA virus, called severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2). The genomic information of SARS-CoV-2 has been studied and published. It contains several open reading frames (ORFs) that encode the spike (S) glycoprotein, the replicase polyprotein, membrane (M), envelope (E), nucleocapsid (N) proteins, and accessory proteins (Walls et al, 2020).
However, the global spread SARS-CoV-2 virus has a high ability on evolution and mutation (Islam et al, 2020). Based on the previous phylogenomic analysis reveals on three major branches of the virus RNA genomic mutation locate in Asia, America, and Europe (Makizako et al, 2019), the mutation of the virus is highly base on the location. It means that different locations may have different mutations. And because that the mutations can affect the pathogenesis of the virus. The development of vaccines may also be affected. Different vaccines may only effective in different regions, and even some vaccines may only be effective in a special period or no longer effective in the future.
Research Questions:
1) Does the SARS-CoV-2 virus have divergent mutation patterns in different geographic locations?
2) Is the mutation of the SARS-CoV-2 genome sequence predictable? Which model will best fit to do the prediction?
3) Whether these base mutations can be converted into amino acid mutations and then affect the function of the protein?
4) Do these mutations show different trends in different regions? Will this affect vaccine development strategies or different morbidity and mortality in different regions?
Hypotheses:
1) The mutation of the virus is highly base on the location.
2) We could predict the trend of the mutation. The prediction should also base on location.
3) Through checking the synonymous and nonsynonymous mutation, we also should identify important mutations that affect the protein function of the SARS-CoV-2 virus.
4) If the function of essential proteins is changed, for example, S protein, it may affect the development of vaccines in different regions. We will develop a visualization system (a website) that would be helpful to attract public attention to this issue.
Data Analysis Procedures:
The sequence data are collected from an open-source website and managed by python code. The website is https://bigd.big.ac.cn/[1]. After downloading the data from the database, we categorize the sequences based on the sample location information, such as continents. We then arrange the data in each continent by sampling time, calculate the mutation frequency in each site of the SARS-CoV-2 genome, and identified the characteristics of mutations in three regions, as well as the change of these mutations over time. As the mutation takes in different types, we will remove the rare variants and focus on the mutations that would cause amino acid substitution in future work. We will assess whether the amino acid substitution affects the protein structure or function.
Focusing on those amino acid substitutions, we will use the ARIMA model (Benvenuto et al, 2020), which is specialized in seasonal variation, to predict the mutation frequency based on time in each region. Then, using other better fit models to predict the mutation rate afterward, we could find out the mutation tendency on each of those codings. With this biological mutation tendency and the geographic differences, we can detect the possibility of a further outbreak of COVID-19, the toxicity of the virus, the source of the new virus, and the effectiveness of the vaccine. We will also develop a website to visualize the data using graphs and update the latest real-time results.
Prospective:
This study is one of many COVID-19 studies, focusing on the prediction of genomic mutation in the future. At the same time, the purpose of this study is to provide the public with a visualization system that can predict the trend of virus transmission and mutation.
Reference
[1]Benvenuto D, Giovanetti M, Vassallo L, Angeletti S, Ciccozzi M (2020) Application of the ARIMA model on the COVID-2019 epidemic dataset. Data Brief 29: 105340
[2]Islam MR, Hoque MN, Rahman MS, Alam A, Akther M, Puspo JA, Akter S, Sultana M, Crandall KA, Hossain MA (2020) Genome-wide analysis of SARS-CoV-2 virus strains circulating worldwide implicates heterogeneity. Sci Rep 10: 14004
[3]Makizako H, Tsutsumimoto K, Doi T, Makino K, Nakakubo S, Liu-Ambrose T, Shimada H (2019) Exercise and Horticultural Programs for Older Adults with Depressive Symptoms and Memory Problems: A Randomized Controlled Trial. J Clin Med 9
[4]Walls AC, Park YJ, Tortorici MA, Wall A, McGuire AT, Veesler D (2020) Structure, Function, and Antigenicity of the SARS-CoV-2 Spike Glycoprotein. Cell 181: 281-292 e286
[5] The data interface source: ftp://download.big.ac.cn/GVM/Coronavirus/vcf/2019-nCoV_total.tar.gz
Questions and Answers
1. What was the major objective of your project and what was your plan to achieve it?
In the project, my work is based on the genome of the SARS-COV-2 virus which caused the COVID-19 pandemic last year. The major objective was to predict the genome mutation patterns using computational modeling. I expected the modeling would show us different patterns in different geographical regions and which sites could be the most important in affecting the mutation of the virus. The prediction might provide an alternative reference for other research and vaccine applications.
In the spread of COVID-19, the mutation of the SARS-COV-2 virus has been found, and scientists imply that the mutation may affect the spread of the virus. So, I planned to predict the mutation and find out the characteristics of the mutation, and then develop a website to show the predicted results in real-time.
To achieve this, my plan was as follows, as written in my research plan:
1) Collect virus sequence data from the open-source database.
2) Categorize the sequence mutation based on sampling locations as some reports indicated the mutation was regional.
3) To predict the mutation trend, organize the data into time series, calculate mutation frequencies and disregard the low-frequency sites.
4) Fit the data with the ARIMA model (a statistical model I used before) for prediction.
5) Assess whether the mutations would cause amino acid changes or not.
6) At last, build a website for others to access my prediction results and display the mutation trend in real-time automatically.
a. Was that goal the result of any specific situation, experience, or problem you encountered?
After the COVID-19 pandemic breakout in the US, the schools, including mine, had to close. During that time, I had to stay home and took online classes, and I checked the case counts hoping for the end of the disease. At school, I have interests in computer sciences, so I learned a lot of knowledge on building models using computer science, then I tried to build a model for predicting the cases of COVID-19. My mathematical supervisor introduced the ARIMA model to me and I found the model is working very well in predicting the cases of COVID-19 which is data with time series. After that, I started to think about what other predictions I could do. From the news, I learned that the virus had been continuing to mutate. Experts said that its pathogenicity and transmission are constantly changing with the mutation. Because most vaccines are using a special site on the virus genome to detect and bind with the protein to inhibit the activity of the virus, the mutations may affect the development of the vaccine and sometimes make the vaccine ineffective. And this gave me an idea that I can use my computer science and math skills to model the mutation rate for every genome site, and this would give me a mutation trend of the COVID-19 virus. And if I use the ARIMA model which I’ve learned from predicting cases on predicting the mutation rate of important sites for COVID-19, It can show different patterns of virus mutation in different countries. Such predictions might help scientists evaluate the tendency of mutation for each site, which could help them estimate the effectiveness of the vaccine in the long term and the possibility of using one vaccine which develops in one region in another region.
b. Were you trying to solve a problem, answer a question, or test a hypothesis?
I was trying to solve a problem that there’s no specific evaluation model on the possibility of mutation. Of course, it is based on a hypothesis that the virus mutation is predictable.
2. What were the major tasks you had to perform in order to complete your project?
Prior to the prediction:
Before the prediction, data acquisition and data cleaning were very important and heavy.
I had to compare and collect a sufficiently large amount of data from many different open-source websites to build a credible, accurate, and real-time database. I had to filter through all the data to make sure they contained necessary information without pre-processing.
Communication was also very important, without sufficient communication, some problems may occur after you finish everything, and you may have to redo the entire thing.
The first time when I obtained data from the CNCB database, the administration of the database suggests me to collect data from a special portal, it can give me every mutation data and the information of sequence in one file. Although the data had a special format inconsistent with data from other sources, I still spend a whole week understanding the format and building programs to extract information that I think is useful.
However, after I use my code to format the data into what we can read, I found that the data have already been pre-processed, that all the back mutations were removed. But, the back mutation information was VERY important for my analysis, so I had to ask the administrator to point me to other data sources to restore the back mutation. And after he gives me the new data, I have to redo the entire thing to reformat the data again to what I can read and use.
Prediction:
After collecting data and translate it to what we can use, I can finally start my prediction
- Categorize data based on location. This is an important step but relatively easy to do. We classified those data according to continents because previous works showed the possibility of different trends in different continents.
- Organize data into time series and calculate the mutation frequency.
- Fit the data using the ARIMA model to obtain predictions. Because I should predict every single site separately, editing model parameters by hands would not be humanly possible. So, I designed an automatic parameter selection flow according to the ARIMA model and spent time building a program to automatically evaluate the parameters. For some predictions, data should also be truncated to remove the interference from low sampling numbers due to early reports (if a single new data will cause a more than 3% mutation rate change), because the mutation rate was calculated based on a single reference.
- Assess whether the mutations would cause amino acid changes. This task requires reading the genome sequence and find its corresponding amino acid changes from literature and data sources.
a. For teams, describe what each member worked on.
No team members were involved in this project.
3. What is new or novel about your project?
The novelty of this project is that I first proved that the virus mutation is predictable. Still, the mutation trends are different for different genome sites and different geographical locations.
Secondly, most studies focused on the prediction of COVID-19 cases, and very few studies focus on single-site mutation prediction. I used a relatively simple model to predict the trends for each site which could be a useful innovation.
Additionally, I used public data to proceed with this project. It can be called data reuse or data mining. In my project, a website is under construction to collect this public data, visualize it and make predictions in real-time to better popularize this important genetic information.
a. Is there some aspect of your project's objective, or how you achieved it that you haven't done before?
Yes, there are plenty of aspects that I haven’t done before. For example, although I used the model (ARIMA) before, applying the model on genome sequence mutation rate is something I haven’t done before. For past projects, I could apply modeling directly on the raw data; but in this project, I had to understand and calculated time series out of the raw data before modeling could be applied. Besides, the bioinformatics aspect of the project’s objective is another new challenge for me. I tried to combine knowledge of biology and mathematical modeling to solve prediction problems. The transformation and interpretation of knowledge brought about by inter-disciplinary have not been encountered in my previous studies.
b. Is your project's objective or the way you implemented it, different from anything you have seen?
Yes, most of the website database which we have seen before is only showing the raw data or some processed data, such as GeneBank from NCBI (The National Center for Biotechnology Information), GISAID (a global science initiative and primary source) and CNCB-2019nCoVR (China National Center for Bioinformation 2019 Novel Coronavirus Resource) database. Most of them are focusing on showing the data in many statistical ways, however, they didn’t do the prediction on the mutation yet.
c. If you believe your work to be unique in some way, what research have you done to confirm that it is?
For start, I had done a literature review on COVID-19 predictions, and I find that most of them which may be related to my project are focusing on the statistic on SARS-COV-2, such as comparing the mutation of virus in a different region to trace to the source, or prediction on the cases number, or predictions on the effect of amino acids and proteins. Diverse mutation of virus in different regions is consistent with other reports which confirm the reliability of my results.
4. What was the most challenging part of completing your project?
In my project, the most difficult thing is to understand the expertise from vastly different research areas and to combine the knowledge.
My project is a product entirely of my own design, and it is not aligned with any of the main research topics of my previous experience and all the researchers we were able to ask for help from. It is totally exciting to do it independently, but it is challenging for me to understand all the math, computer science, and biology knowledge from experts’ inputs and proceed with the project on my own with a few experts supervise and suggestions.
Besides consulting to obtain suggestions and validate them by trial-and-error, I often needed to translate the computational based work into a different, biological language, describing the modeling reasoning in a way that can be understood by a bioinformatics researcher, or put the genome sequence data into something meaningful for a pure mathematician.
Working on a new interdisciplinary project, without any professional forerunners, sometimes get me into communication issues (such as the terminology across different research areas that can cause misconception). For example, during the data collection, the data suggested by the biology experts did not meet the requirements suggested by my computer science advisor. I had to work carefully to validate all the data, suggestions, and requirements to make sure I did not train the model with some wrong data.
a. What problems did you encounter, and how did you overcome them?
- Learning specialized research articles from different research areas was a big challenge. My solution was to put more effort and more time into the project. I checked new concepts on the web and read research articles over and over again. I also kept close contact with some experts and ask them for directions on how to learn that new knowledge.
- Combining knowledge from different research areas requires a lot of back-and-forth communications and validations. For example, for the biology questions -- which important site may affect the structure of a virus, I would learn from a biology expert and used the biological criteria to select an important genome site. With that knowledge, I turned to an expert in math modeling and asked him for the suggestion on how to build models for quickly changing time series. The results of the modeling must be explained and validated in biology backgrounds, and I had to figure out the biological meaning of the parameters and predictions and explained to my biology advisor so we can validate the model and change the parameters and do another round of model fitting.
- During the programming, because the size of data was very large, I needed to build codes for the “batch” operation of a group of files, even for very simple tasks. I had to carefully debug the code and used unit-testing very frequently.
b. What did you learn from overcoming these problems?
I learned how to explain things in different ways to experts in different areas. Such as when I’m trying to explain the meaning of data to a modeling expert, I have to use the mathematical way to explain it. So, he can give me a more specific suggestion on how to design the model based on the mutation rate data. And after I built the model, I have to explain the predictions to biology experts using a biology tone.
5. If you were going to do this project again, are there any things you would do differently the next time?
- I could choose to use and compare more professional models for prediction. Some other Machine learning models are reported to be very powerful in doing predictions for time series too, and if I have more time, I would add AI models into the predictions.
- With more knowledge on the biology data and database, I could more easily design a better data collection process so I will not waste time and effort on wrong data or wrong formats.
- Time management throughout the year. I would start the project earlier, to make time for other important school and science events during the project year.
a. Did working on this project give you any ideas for other projects?
Working on this project gave me quite a lot of ideas in using mathematics and computer science in the biology area like using simple modeling for protein prediction and in the computer science area like using machine learning and AI for modeling and prediction on virus mutation or medical diagnosis.
7. How did COVID-19 affect the completion of your project?
PRO: COVID-19 gives me inspiration for this project, which can help me apply computer science skills and math to something affecting the entire world.
CON: It makes communications with other people less convenient. Online communications are less efficient compared to in-person meetings and sometimes easily lead to miscommunications. I had to overcome this with more frequent contact with my advisors and learn things more in a trial-and-error way.